

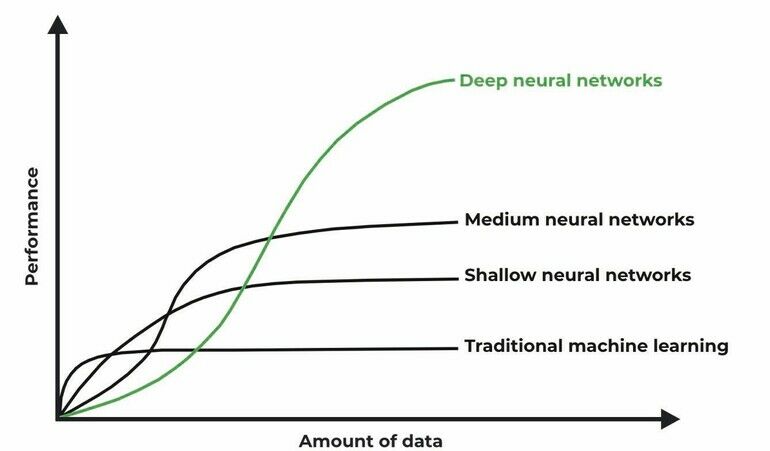
Mythos 1 lautet: Je mehr Daten desto besser. Jeder der sich schon einmal mit dem Thema KI beschäftigt hat, weiß, dass digitale Daten der Schlüssel zum Erfolg sind. Eine KI lernt in den häufigsten Fällen, was man ihr zeigt. Dabei gilt: je mehr desto besser. Die bildbasierte Fehlererkennung ist dabei ein typisches Einsatzgebiet in der Qualitätssicherung. Das Problem: Man braucht einen möglichst diversen Datensatz – sonst lernt die KI nur, was sie sowieso schon kann. Wenn Anbieter von KI-Lösungen von vielen Daten sprechen, meinen sie meist nicht 100 Bilder sondern eher x0.000 oder mehr. Wenn man etwa ein KI-System zur Beurteilung der Qualität von Schweißnähten anhand von Röntgenfilmaterial aufbauen und dabei auftretende Fehlerbilder automatisch erkennen möchte, findet sich Bilddatenmaterial mit dem Fehlertyp Poren meist zur Genüge. Kritische Fehlertypen wie Risse sind deutlich seltener zu finden.
Ein weiterer Fallstrick liegt im Aufnahmezeitraum. Angenommen, man trainieret eine KI auf den Daten von Januar bis Juni. Dann wechselt die Aufnahme-Hardware zum Beispiel Licht oder Kamera. Die Wahrscheinlichkeit, dass die KI jetzt nicht mehr funktioniert, ist hoch, obwohl sie vielleicht schon tausende Bilder zum Training genutzt haben. Ähnlich verhält es sich beim Wechsel zwischen Anlagen. Man hat die Bilder einer einzelnen Anlage zum Training verwendet und will nun auf 30 weitere, leicht unterschiedliche ausrollen. Die KI – oder besser gesagt Deep Learning – kann indes lernen, diese Einflüsse zu minimieren, wenn sie verschiedene Daten zum Training erhält und man diese Problematik vorher antizipiert.
Was außerdem häufig nicht berücksichtigt wird, ist die Güte des aktuellen Qualitätskontrollprozesses. Häufig hört man, die KI sollte mindestens so gut sein, wie das aktuelle System oder der Mensch, der derzeit prüft. Häufig wird dann der Fehler gemacht, dass diese als 100 % genau angenommen werden – man also eigentlich keine statistische Aussage darüber hat, wie gut ein aktuelles System oder der Mensch arbeitet. Wenn die KI dann etwa gelabelte Daten von einem strengen Prüfer als Trainingsgrundlage verwendet, aber ein zweiter Prüfer vielleicht hier und da noch „ein Auge zudrückt“, kann man sich vorstellen, dass bei Einsatz der von der KI ermittelte Ausschuss ansteigt, obwohl sie eigentlich nichts falsch erkennt. KI-Modelle reagieren in solchen Fällen genau wie Menschen mit „Verwirrung“. Daher sollte man versuchen, eine Balance zwischen den Fehlerklassen und möglichen Variationen bei der Erstellung des Datensatzes zu finden und sich vorher über die Güte des aktuellen Prozesses Gedanken machen.
Nicht jeder Anwendungsfall
benötigt Künstliche Intelligenz
Mythos 2 lautet: Schneller, besser, weiter. „Geben Sie uns 100 Bilder und sie erreichen 99 % Genauigkeit.“ Solche Sätze führen zu falschen Erwartungen. Neben der Datenproblematik gilt auch, dass nicht jeder Anwendungsfall eine Künstliche Intelligenz braucht. Wozu sollte man eine KI mit viel Aufwand trainieren, wenn eine simple Lichtschranke schon ausreicht? Manchmal sind auch einfache regelbasierte Algorithmen ausreichend und sogar schneller. Ein KI kann mit viel Grafikkartenpower sehr schnell werden. Aber je komplexer die Aufgabe, desto länger dauert die Berechnung. Eine einfache Fehlerklassifizierung IO-NIO kann schnell gehen, während eine pixelgenaue Fehlersegmentierung viel länger braucht.
KI sollte ins Spiel kommen, wenn andere Lösungen an ihre Grenzen kommen. Oft ist auch ein Zusammenspiel aus regelbasiertem und KI-Algorithmus die optimale Lösung für ein Problem. In der industriellen Radiographie werden zum Beispiel Bildgüteprüfkörper verwendet, um eine ausreichende Bildqualität festzustellen. Dazu werden sogenannte Doppeldrähte neben das kontrollierte Bauteil gelegt. Eine KI könnte dann zum Beispiel die Position dieser Doppeldrähte feststellen und ein regelbasierter Algorithmus eine Kontrastbewertung nach Norm vornehmen. So kann man das Beste aus beiden Welten kombinieren.
Die KI kann längst nicht alles
automatisieren
Mythos 3 heißt: Die KI kann alles automatisieren. Ja, es gibt viele Arbeitsschritte, die verhältnismäßig leicht mit KI gelöst werden können und schon einen Großteil an Arbeitszeit einsparen. Bei anderen Arbeitsschritten ist aber viel Detailarbeit notwendig, um jede Eventualität abzudecken, sodass es sich unter Umständen nicht rentiert. Eventuell läuft die Qualitätssicherung bereits im aktuellen Betrieb auf gutem Niveau, das heißt, es gibt nur einen Drang zur Optimierung, wenn Reklamationen oder Pseudoausschuss ein Thema sind. Häufig bietet sich daher eine Effizienzsteigerung durch KI an statt einer Vollautomatisierung. Man kann anhand von Wahrscheinlichkeiten, die das KI-Modell ausgibt, feststellen, wie sicher sich das Modell ist. Vielleicht reicht es, wenn ein Mensch dadurch nur noch jedes 100. Teil prüfen muss, genau an den Stellen, wo sich das Modell unsicher ist. Zudem kann man auch eine Vorsortierung von Bilddaten durchführen. Man denke an einen
Turnaround einer Raffinerie. In der Praxis gibt es oft Fälle, wo auf 95 % der Aufnahmen alles in Ordnung ist und nur 5 % zeigen Fehlermerkmale. Findet man diese 5 % schnell, so können hier eventuelle Stillstandszeiten minimiert werden. Wir plädieren dafür, KI als zusätzliches Werkzeug zu sehen. Es gibt Anwendungsfälle, wo Mensch und KI zusammenarbeiten müssen, um optimale Ergebnisse zu erzielen.
Mythos 4 lautet: Einmal entwickelt, lernt die KI von alleine – und das auch im laufenden Prozess. Dies ist ein Irrglaube. In der Praxis sind diese Algorithmen nicht weit verbreitet. Ebenso falsch ist die Annahme, dass nach einmaligem Training alles perfekt funktioniert. Wie erwähnt, ist das Datenthema entscheidend. Häufig werden erst alle Grenzfälle, von denen wenig Daten vorhanden sind, nach längerem Live-Betrieb klar. Im Produktionsumfeld sind zudem Faktoren wie verschiedene Produktionslinien, Werkzeugtypen oder Bauteilgruppen relevant.
Man sagt, dass die KI-Modell-Entwicklung zu 80 % daraus besteht, einen Datensatz zu erstellen und aufzubereiten. Dies geschieht nicht einmalig, sondern auch mit neuen Daten, die im laufenden Betrieb oder einem längeren Zeitraum gesammelt wurden. Der Vorteil einer KI ist, dass man ihr diese seltenen, aber kritischen Aufnahmen zeigen und ihr diese Fälle durch ein neues Training beibringen kann. Ebenso sind kollaborative Verfahren möglich, bei denen eine KI neue Daten voranalysiert und die Ergebnisse durch den Menschen korrigiert werden. Hat man genug Daten korrigiert, kann ein neues KI-Training beginnen.
Training bedeutet, vereinfacht gesagt (bei Neuronalen Netzen), eine mathematische Optimierung von Gewichten an jedem Knotenpunkt des KI-Modells. Dieser reine Rechenvorgang dauert in der Regel mehrere Stunden oder Tage und benötigt leistungsstarke Hardware. Neue Bilder und ihre Bewertung verändern bei einem Training somit die Gewichte im Vergleich zum Vorgänger-Modell. Dies geschieht jedoch nicht, wenn man dem Modell ein Bild nur „zeigt“ – so wie es im laufenden Betrieb wäre.
Die Anpassung (Training) eines KI-Modells ist daher ein iterativer Prozess. Data Scientisten testen verschiedene Netzwerkarchitekturen und Parameter, spielen immer wieder Daten zum Training ein und vergleichen die Ergebnisse. Der Aufwand pro Iteration verringert sich in der Regel pro Schleife, da das Modell immer robuster wird. Bei regelbasierten Ansätzen aus der klassischen Machine Vision müsste ein Entwickler (im Vergleich zum „Beispiel-basierten“ Lernen einer KI) für jeden Sonderfall neue Regeln definieren. Zum Beispiel: wenn der Kontrast an einer Stelle XY mit dem Radius Z den Wert 120 überschreitet, ist dies ein Bauteilfehler. Für einfache Zusammenhänge kann man dies noch gut abdecken, aber ab einem gewissen Punkt lohnt sich der Einsatz von KI, da sie die Zusammenhänge des Bilds „versteht“.
KI kann auch helfen, das Rauschen aus Bildaufnahmen zu entfernen
Mythos 5 ist: KI eignet sich nur, um Fehler auf einem Produkt/Bild zu erkennen. Die Praxis zeigt aber, dass es neben der Erkennung von Fehlern auf Bildern oder der Klassifizierung weitere Anwendungen relevant sein können. Ein Thema, das für den industriellen Einsatz immer relevanter wird, ist das Image Enhancement, also die „Bildverbesserung“. In der Radiographie oder der CT kann es zum Beispiel vorkommen, dass Bauteile Minuten lang bestrahlt werden, um eine nicht verrauschte Aufnahme zu erhalten. Eine kürzere Bestrahlung kann dabei Geld sparen, aber verrauschte Aufnahmen generieren, wo mögliche Fehlstellen dann im Rauschen untergehen und nicht mehr erkannt werden können. Sentin nutzt KI, um das Rauschen aus solchen Aufnahmen zu entfernen, aber gleichzeitig Fehlstellen zu rekonstruieren. Die KI lernt, kleine Nuancen in den Grauwerten einzelner und umliegender Pixel zu interpretieren und Zusammenhänge zu erkennen, die das menschliche Auge beziehungsweise Monitore nicht richtig darstellen können. Radiographische Aufnahmen weisen nämlich mindestens 12 Bit, eher 16 Bit Grauwerte auf, was dem 16-fachen beziehungsweise 256-fachen eines normalen 8 Bit JPEG Bilds mit 256 Graustufen entspricht. Dadurch ließe sich die Bestrahlungszeit und damit die Durchlaufzeit pro Bauteil drastisch reduzieren. So kann KI auch in anderen Anwendungen als der klassischen Fehlererkennung genutzt werden.
Sentin GmbH
Südring 25
44787 Bochum
www.sentin.ai







{kind=link}