

Das Reklamationsmanagement ist ein Kernprozess in Unternehmen. Er umfasst die strukturierte Bearbeitung von negativen Rückmeldungen aus dem Anwendungskontext zur Qualität eines Produkts oder einer Dienstleistung zwecks Behebung oder Beseitigung eines Mangels. Kundenfeedback in Form von Reklamationen kann – über den speziellen Einzelfall hinaus – auch zur Weiterentwicklung und Verbesserung der Produkte oder Dienstleistungen beitragen. Ein effizientes Reklamationsmanagement dient sowohl der Kundenzufriedenheit als auch der Produktentwicklung und -sicherheit; es fördert den wirtschaftlichen Erfolg.
Das Reklamationsmanagement ist ein oft repetitiver Prozess mit signifikanten Fallzahlen. Darin liegt ein hohes Potenzial für Künstliche Intelligenz (KI) und automatisierte Prozessschritte. Im Forschungsprojekt „Reklamation 4.0 – Datengetriebene Verbesserung des Reklamationsmanagements im Kontext von Industrie 4.0“ wurde der KI-Einsatz bei Reklamationen anhand von Anwendungsfällen in der Medizintechnik erprobt. Förderung kam vom Bundesministerium für Bildung und Forschung im Rahmen von „KMU innovativ“.
KI kann in Form von Deep Learning und auf Basis von Vergangenheitsdaten beziehungsweise jeweils aktuellen Prozessdaten eingesetzt werden. Die Daten stammen aus früheren Reklamationen oder Produktionsprozessen. Es geht um Prozessausführungsdaten, Sensordaten, Maschinendaten etc. Damit wird ein neuronales Netz trainiert und für mögliche Anwendungsszenarien vorbereitet.
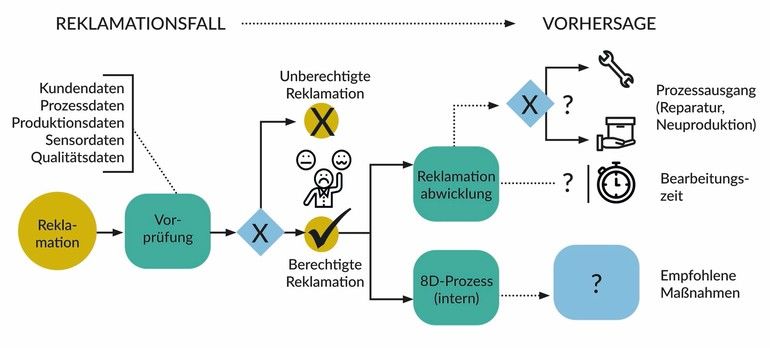
Ein Anwendungsszenario ist die Qualifizierung von Reklamationen: Reklamationen werden aufgrund von Entscheidungen aus der Vergangenheit automatisch etwa hinsichtlich ihrer Berechtigung, Relevanz und Kritikalität qualifiziert. Sie werden Fehlercodes zugeordnet. Die KI führt also eine Vorklassifizierung von Reklamationen durch. Dies verkürzt die Dauer bis eine Reklamation bei den zuständigen Mitarbeitern bearbeitet wird. Ein weiteres Anwendungsszenario ist die Ergänzung von Reklamationsdaten: Diese werden mit zusätzlichen Informationen zur möglichen Bearbeitungszeit, zur Zuständigkeit, zu passenden Maßnahmen und erforderlichen Ressourcen etc. angereichert. Auch hier wird auf historische Daten und Erfahrungswerte zurückgegriffen. Möglich ist der Einsatz von KI auch bei der Automatisierung der Reklamationsabwicklung: Reklamationsprozesse können automatisiert ablaufen; eine Massenbearbeitung von Reklamationen ist möglich. Reklamationen, die mit einer hohen Frequenz auftreten, werden so ohne Wartezeit sortiert und weiterbearbeitet. Kunden erhalten zum Beispiel eine automatische Benachrichtigung über die voraussichtliche Bearbeitungszeit. An die KI-basierte Auswertung schließen sich Folgeaktion an: Fehlermeldungen werden in einem digitalen Managementsystem angelegt und über vorhandene Workflows weiterbearbeitet. Beispielhaft wurde dies im integrierten Managementsystem DHC Vision realisiert: Maßnahmen zur Reklamationsbehebung werden automatisch eingeleitet, 8D-Reports automatisch vorbefüllt, Capa-Prozesse (Corrective and Preventive Action) angestoßen etc. Auch können Auswertungsergebnisse an ein ERP-System weitergegeben werden, wo dann beispielsweise der von der Reklamation betroffene Batch gesperrt wird.
Eine weitere mögliche Anwendung ist die Vorhersage von Reklamationen: Reklamationsrelevante Abweichungen werden bereits im Produktionsprozess erkannt und über Frühwarnprozesse verhindert. Schon auf der Produktionsebene kann vorhergesagt werden, ob zum Beispiel eine Charge mit einer gewissen Wahrscheinlichkeit zu Reklamationen führen wird, weil es zu Abweichungen bei der Temperatur kam. Grundlage für dieses präventive Reklamationsmanagement liefern Maschinen- oder Sensordaten, also Daten aus den produktionsnahen Prozessen. Werden multiple Datenquellen in den Vorhersagemodellen berücksichtigt, stärkt dies die Objektivität der Voraussage. Daten oder Kombinationen von Parametern, deren Relevanz nicht offen ersichtlich ist, können erkannt und einbezogen werden.
Hohe Qualität der Daten ist eine wesentliche Voraussetzung
Voraussetzungen für den KI-Einsatz betreffen insbesondere die verwendeten Daten und ihre Qualität. So müssen Reklamationen in Freitextform von der KI analysiert werden. Die Spracherkennung erfolgt durch ein neuronales Netz, das mit bereits klassifizierten Reklamationstexten trainiert wird. Dafür ist eine hinreichende Anzahl an Texten notwendig. Sie ist abhängig von der Anzahl der Klassen (Fehlercodes), der Schärfe der Abgrenzung der Codes und der Datenqualität. Wie viele historische Reklamationen benötigt werden, lässt sich nicht allgemein, sondern nur durch Tests beantworten. Wahrscheinlich braucht es eine hohe vierstellige Zahl (etwa bei binärer Klassifikation) mit möglichst gleichverteilten Daten. In jedem Fall ist ein effektives Datenmanagement im Unternehmen für den KI-Einsatz unerlässlich.
Historische Reklamationsdaten können für eine KI herangezogen werden, die zur Klassifikation von Reklamationen angelernt wird. Die Daten enthalten eine textuelle Beschreibung des reklamierten Produkts, die zugeordnete Kritikalität sowie den internen Fehlercode. Sie bilden die Grundlage für eine automatisierte Auswertung mittels eines rekurrenten Long short-term memory (LSTM) (deutsch: langes Kurzzeitgedächtnis) Netzes. Für die Datenauf- und -vorbereitung werden Methoden wie automatisierte Spracherkennung und Übersetzung sowie ein Clustering eingesetzt. So werden die in den Daten real abgebildeten Fehler – im Gegensatz zu den historisch zugeordneten Fehlern – ermittelt. Ähnliches gilt für schriftliche Projektberichte des Außendiensts: Auch sie werden via Texterkennung analysiert. Es erfolgt eine semantische Auswertung von Fehlerzuordnungen.
Vor dem KI-Einsatz sind in der Regel mehrere Datenbereinigungsschritte erforderlich. Eine Tokenisierung und Vektorisierung der Daten muss vorgenommen werden. Dieser vergleichsweise hohe Aufwand ist einmalig zu leisten. Ähnliches gilt für den Aspekt „Sprache“: Das neuronale Netz ist semantikabhängig auf eine Sprache trainiert. Jede weitere Sprache stellt also eine Untergruppe von Daten dar, die von der Gesamtmenge und damit der Trainingseffizient abgeht. Eine vorherige, semantisch korrekte Überführung der Reklamationsdaten in eine Sprache ist daher empfehlenswert. Historische Fehlerzuordnungen weisen oft keine balancierte Datenverteilung auf und verursachen so eine ineffektive Klassifizierung. Redundanzen und fehlende Codes sind möglich. Es empfiehlt sich, zunächst die tatsächliche Verteilung der Fehlercodes zum Beispiel mittels Clustering zu analysieren und die Datencluster mit den erforderlichen beziehungsweise gewünschten Fehlercodes zu vergleichen. Aufgrund des exponentiell steigenden Datenbedarfs mit jedem zusätzlichen Fehlercode sollten Klassen gegebenenfalls gruppiert werden. Es ist zu entscheiden, wann welche Unterkategorie notwendig wird.
Ein regelmäßiges Re-Training ist notwendig
Berücksichtigt werden muss auch, dass sich die Datenbasis weiterentwickelt. Eine periodische Überprüfung sowie ein Re-Training sind erforderlich, um den Algorithmus gegebenenfalls an geänderten Voraussetzungen anzupassen. Sonst besteht die Gefahr eines Concept Drift: Reale Daten und KI-Modell entwickeln sich auseinander. Auch punktuelle Ereignisse können zu einer Änderung der Grunddaten führen; so führt eine fehlerhafte Charge zu mehr oder anderen Reklamationen in einem bestimmten Bereich. Dies kann zum Teil durch die Flexibilität des Modells abgefangen werden, in Summe und über die Zeit aber zu einem Qualitätsverlust führen. Ein Re-Training ist aber weniger aufwändig als das ursprüngliche Setup. Es hält eine KI auf dem aktuellen Stand.
DHC Business Solutions GmbH & Co. KG
Landwehrplatz 6–7
66111 Saarbrücken
Tel. +49681936660
www.dhc-consulting.com
 Bilder: DHC
Bilder: DHC Bilder: DHC
Bilder: DHC Bilder: DHC
Bilder: DHCDr. Wolfgang Kraemer Dr. Heike Sander Dr. Jan Riehm
Geschäftsführer
Senior Researcher
Senior Researcher
DHC Business Solutions · www.dhc-vision.com
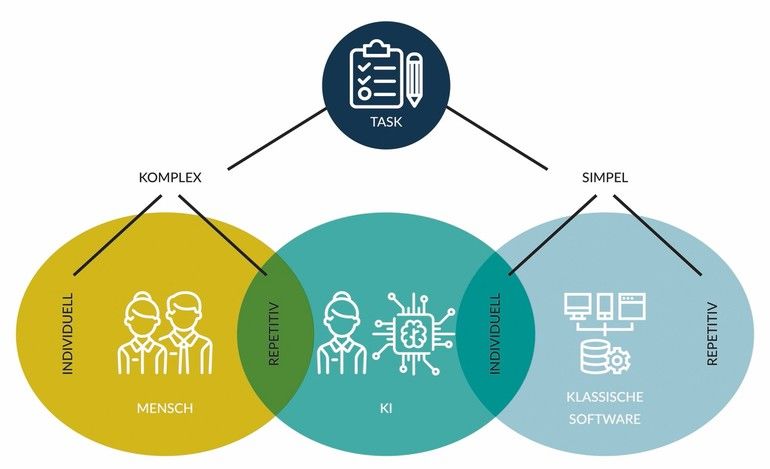
Kein Ersatz für Menschen
Das Projekt zeigt: Sofern eine qualitativ wie quantitativ ausreichende Menge an Daten vorhanden ist, ist ein KI-gestützter Reklamationsprozess möglich. Es können deutliche Mehrwerte beispielsweise hinsichtlich Zeit, Ressourcen und Sicherheit erzielt werden. Klar muss sein, dass eine KI den Menschen nicht ohne weiteres ersetzen kann oder soll. Zielführend ist ein Vier-Augen-Prinzip, das Mensch und Maschine sowie Sicherheit und Effizienz zusammenführt und Datenschutzvorgaben berücksichtigt. Sachkundige Begleitung beim Implementieren und Validieren einer KI-Lösung ist unerlässlich.







{kind=link}